Does Watermarking Protect Against Deepfake Attacks?

Nick Gaubitch
Director, Research • October 20, 2023 (UPDATED ON October 30, 2025)
6 minutes read time
Recent leaps in the field of generative AI, in combination with a plethora of available data, has resulted in numerous tools that are able to generate highly convincing audio and video deepfakes. This includes both fully synthetic identities but also synthetic voices and voice cloning.
While much work at Pindrop research has gone into developing tools for accurate deepfake detection, we believe that more can be done to protect users from malicious or misleading use of deepfakes. One such path is to use digital audio watermarking to aid the distinction between live and synthetically generated speech. The vision here is that all synthetically generated speech is watermarked but like any other opportunity, it does not come without its own challenges. Most watermarking technology has been applied to images and it is already used for AI generated images1.
Here we introduce the basics of audio watermarking and discuss the particular challenges that arise if this was to be used for speech at call-centers. In summary, the use of watermarking would be a good start but it will not alone solve potential threats posed by deepfake speech for two reasons. First, there is an implicit assumption that all deepfakes will be watermarked, which will be difficult to enforce and second, the acoustic and phone channel degradations makes watermarking more vulnerable to attacks. It’s not surprising that researchers at University of Maryland found it easy to evade current methods of watermarking. Multiple academic institutions shared their skepticism on the efficacy of watermarking, in the same article in WIRED2 that outlined the University of Maryland findings. Therefore, at Pindrop we believe that watermarking, especially in the context of audio for contact centers, is not fool proof and should be considered in combination with other advanced deepfake protection tools.
What is digital audio watermarking?
Audio watermarking describes the insertion (or encoding) of a signature signal (watermark) to an audio recording. Much of the watermarking development targets copyright protection of music. A related field is steganography, where the audio signal is used to carry hidden information.
A watermark must be added in a strategically subtle way so as to be both imperceptible to the human ear (otherwise it will impact the quality of the host audio) as well as detectable by a decoding algorithm.
The decoding algorithm exploits knowledge of how and where the watermark has been encoded in the signal to reveal its presence; it may also require a secret digital key if one has been used as part of the encoding process.
The process must be robust to degradations of the watermarked signal. For instance, a music decoding algorithm must be capable of revealing a watermark even if the audio has been compressed or altered (e.g., uploading to YouTube). Finally, depending on how much information we wish to store via watermarking, the capacity can also become a constraint. A watermark must achieve a balance between robustness and imperceptibility (i.e., increasing the watermark intensity will make it more robust, but it can also make it perceptible).
The challenges of watermarking speech for call centers
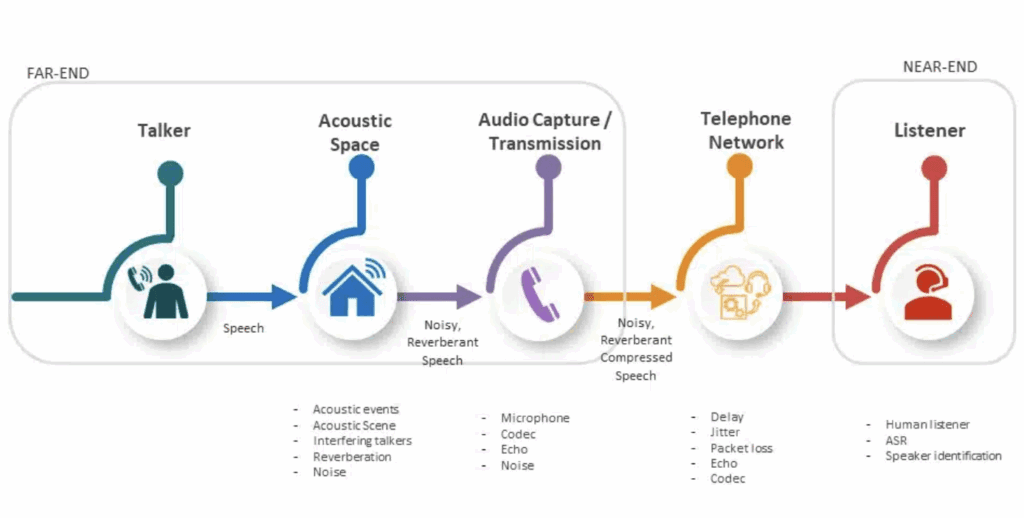
Figure 1. A typical call-path for a speech signal from a talker to a listener highlighting many of the potential sources of degradation a speech signal may encounter in the transmission between a talker and a listener.
Watermarking of speech is inherently a much harder problem than watermarking of music or images due to its narrow bandwidth, its sparse spectral content and ease of predictability. Put simply, in music there is more “signal” within which to add the watermark (i.e., music has greater spectral richness).
The level of robustness required for music-watermarking is not high; music compression causes relatively low quality loss (e.g., MP3). By comparison, if we consider synthetic speech at the contact center, the degradations are significantly more challenging.
The contact center use case is important as different attacks using deefpake speech can be anticipated. For example, it may be used to impersonate a victim to bypass a voice authentication system or to mislead a contact center agent.
Text-to-speech (TTS) engines typically operate at high sampling rates (44.1kHz or 48kHz). As the typical legitimate use case of the synthesized content involves minimal degradations and little or no compression, the watermark perceptibility must be low even at high sampling rates.
Then, there is, of course, the challenge posed by deliberate attacks whereby a malicious attacker applies operations to the watermarked signal to remove or attenuate the watermark.
But even if we were to disregard intentional attacks, the anticipated degradations of the speech signal can be significant. A speech signal may pass from a loudspeaker (ambient noises and delays) and be captured by a microphone (filtering). The telephony channel itself adds degradations (downsampling, packet-loss, echoes, compression) see Figure 1.
Figure 2 illustrates the balance between imperceptibility quantified by the perceptual evaluation of speech quality (PESQ) and watermark detection performance quantified by equal error rate (EER) for two commonly used watermarking methods: the spread-spectrum (SS) and the time-spread echo (TSE). The use of EER in watermark detection is the point where the false alarm rate (detecting a watermark when one is not present) and the false rejection rate (not detecting a watermark when one is present) are equal. For an imperceptible watermark of PESQ greater than 4 the typical performance is in the range of 15-30% EER. Note that both these methods achieve close to 0% EER even in attack types such as additive noise and resampling as shown in Fig. 3. In both cases the parameter that is varied is the watermark strength which governs the tradeoff between quality and performance.
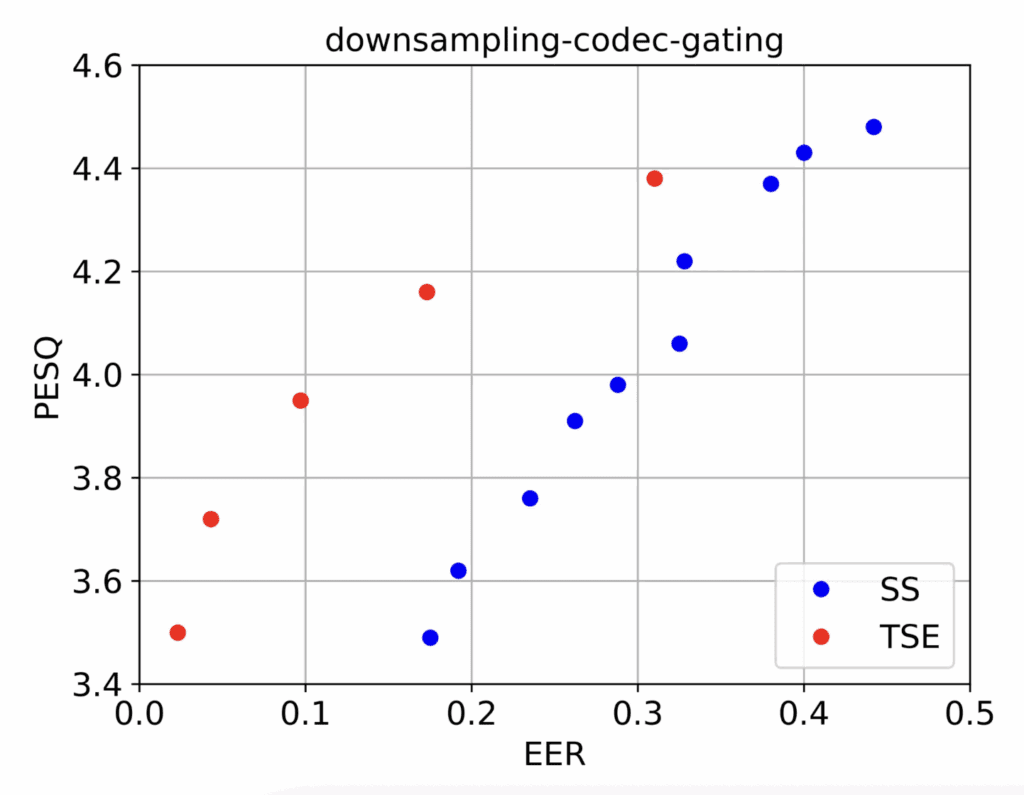
Figure 2. Quality measured in terms of PESQ vs performance quantified by the EER of the watermark detection for two commonly used watermarking techniques, spread-spread spectrum and time-spread echo, in the presence of call-path signal modifications (downsampling, codec at 8 kbps and noise gating).
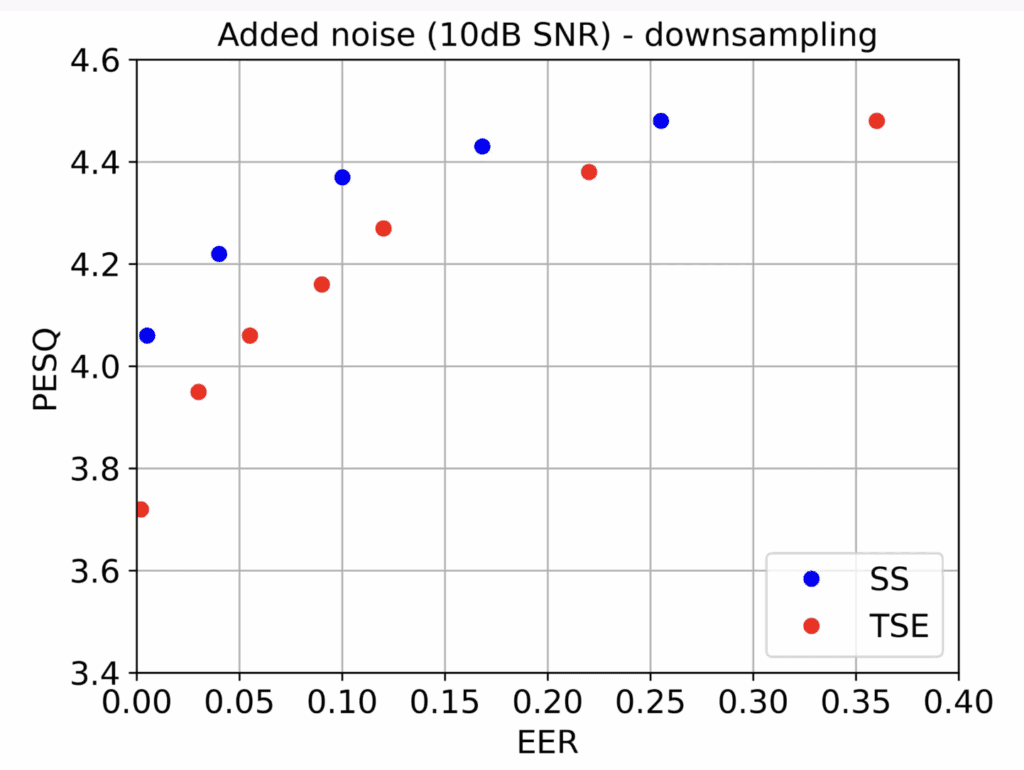
Figure 3. Quality measured in terms of PESQ vs performance quantified by the EER of the watermark detection for two commonly used watermarking techniques, spread-spread spectrum and time-spread echo, in the presence of deliberate signal modifications (additive white Gaussian noise and resampling).
Concluding comments
Deepfake speech poses a risk to contact centers where it may be used to bypass voice-based authentication or impersonation in account takeover attempts. Watermarking could be a good step towards the protection from malicious use of deepfake speech. However, as opposed to previous applications in, for example, music, watermarking that is robust to acoustic and phone channel degradations is a challenge that must be overcome. Moreover, there is an underlying assumption that watermarking can be enforced for all synthetic content, which may not be realistic beyond commercial TTS providers.
Therefore, the sole use of watermarking will likely not be enough and it is preferable to combine this with other sophisticated tools for synthetic speech detection.
1. MIT Technology Review: Google DeepMind has launched a watermarking tool for AI-generated images, Aug 2023
2. Wired.com: Researchers Tested AI Watermarks—and Broke All of Them, Oct 2023
Related research + insights
Access expert research, detailed guides, and practical resources on voice security to strengthen your contact center’s defenses.

Article
Zero Trust Came for the Network. Now It’s Coming for the Human.
July 16, 202612 minutes read time

Article
Deepfake Video Call Scams & BEC: The Case for Continuous Identity Verification
July 7, 202611 minutes read time
