Written by Scott W. Strong
In the first part of this series, I discussed how important it is as a data scientist to ask the right questions when solving a new problem. In this post I will be digging into a specific example relating to the situation when a data scientist is presented with a prediction goal, but no data to support that goal. Specifically, we will be looking at trying to predict the outcome of the NCAA Men’s National Basketball Tournament known as March Madness. But first, let’s review the key questions that should be answered when beginning any problem like this one.
What do we know about the system?
What drives the system’s behavior?
Are there rules or structure that must be followed?
What should we predict?
What can we predict that is both useful and possible?
Some predictions may be very easy to make, but have no utility
Others might be extremely useful, but nearly impossible to make
We need to find a happy middle ground here
What data is available to support our predictions?
Is there an authority on this system that might have data?
NOAA for weather
U.S. Census or Bureau of Labor Statistics for demographics
Etc.
Which prediction techniques should we use?
Should we be using classification or regression?
How much representational capacity should the method have?
How good are our predictions?
Are we doing better than a “dumb” learner?
What’s the performance of a random guess or a simple rule?
What metrics best capture prediction performance?
Given these key questions, let’s explore how we might be able to predict the results of the NCAA Men’s Basketball Tournament. We first need to understand how the tournament is played and what has happened in the past to see what we can leverage for our future predictions.
The March Madness tournament started in 1939, which involved only 8 teams, but that count has been increasing ever since. The tournament has been played with 64 teams since 1985 in a single elimination format, and as the name suggests, is played every year in March. The competition is played in a very structured, bracket arrangement, were each team’s path through the competition can take them to play any other team in the tournament. The bracket is organized such that each of the 4 regions will play within their region until there is one prevailing team from each region. Only then will teams be allowed to play teams from other regions. In some cases, the only way one team can play another is by beating all other teams, meeting in the championship game. Due to this structure, a committee of experts chooses each team’s position within a region based on their perceived skill to have better teams play one another later in the tournament (each team is ranked 1-16 seed for each region — best to worst). The bracket below shows the final results of the 2015 tournament.
It is interesting to note that approximately 25% of all games are upsets! This means that the team with a worse seeding beats the team with a better seeding. Over the years, it has been a long-standing tradition for people all over the US to make their own bracket and pick the winners of each game. Of the approximately 60 million people who fill out brackets each year, there has never been a perfect bracket recorded. In fact, if everyone in the US filled out a bracket every year, the odds of being perfect are so unlikely that it would take around 400 years to see our first perfect one! See this link for more details on that.
Knowing that we want to predict who will win each game, we recognize that this can be accomplished multiple ways. The first way that comes to mind is to determine an expected score difference between every team involved in the tournament. Similarly, we could reduce this to a more “data science” based framework and try and predict the probability of win for each team against every other team. If we think a little bit more, there is another, slightly more attractive alternative. Instead of predicting team vs. team results, we can predict how far a single team will get into the tournament (depth). This modification simplifies the prediction process significantly, so we will try and predict depth first.
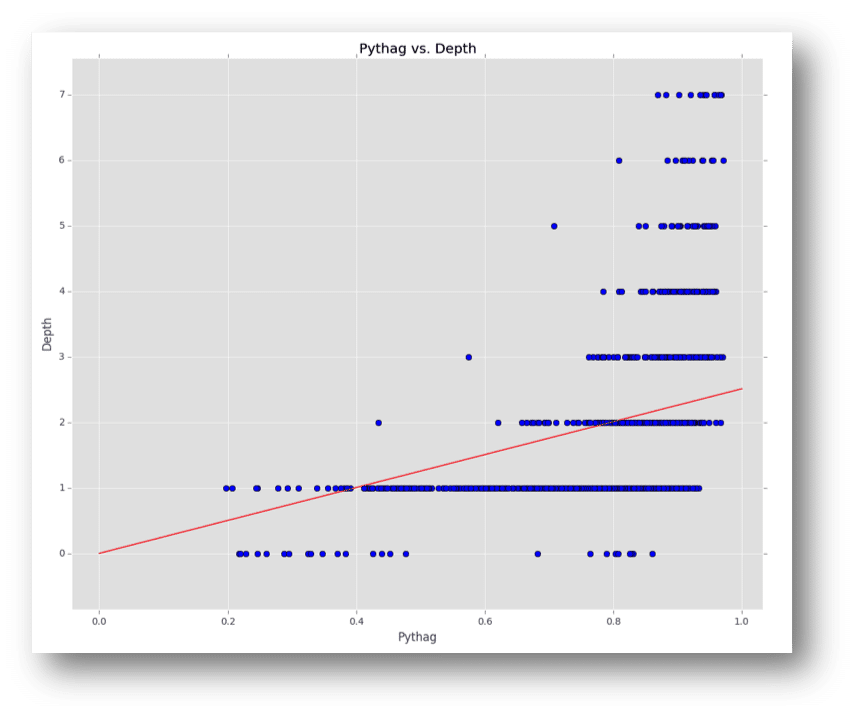
The next thing that we need to figure out is what data is available to support our prediction task. To do this, I explored the many free and paid options for college basketball statistics and found a statistician by the name of Ken Pomeroy who has an extensive account of college basketball statistics, including some of his own metrics. Here is his website if you are interested in checking it out. From this data, we have access to historical team statistics such as shooting percentage, defensive efficiency, strength of schedule, and Ken’s favorite, the Pythagorean rating. If we plot the Pythagorean rating (0.0 is the worst and 1.0 is the best) versus depth in the tournament (what we are trying to predict), we get the following: Observing this chart of data from 2002 to 2014, we can gain a couple pieces of critical information. The Pythagorean rating is actually pretty good at determining the depth of a team, but there still seems to be lots of uncertainty (i.e. there are a variety of Pythagorean ratings for a given depth in the tournament). We will address this shortly. In addition, we see that the relationship between Pythagorean rating and depth is non-linear. The red line shows the best-fit line for this data, and we can see that it doesn’t do a great job of representing the curvature we see. This leads us to a set of requirements we need for the prediction method used for this problem:
Should be a regression technique
Needs to capture uncertainty (possible upsets in the tournament)
Allows for non-linear relationships
Runs in a reasonable amount of time
Using 33 of Ken Pomeroy’s statistics in combination with the results of the tournament (depth) from 2002 to 2012, I’m now ready to plug in a few standard learning algorithms to see how well we do. A good approach to finding the “right” learning algorithm is to start simple (i.e. linear regression, logistic regression, etc.) and then increase the representational capacity (i.e. neural networks, support vector machines, etc.). If you use a really complex algorithm right away for a problem that doesn’t require such complexity, you run the risk of building a model that doesn’t generalize well. There are ways to combat this, but I will leave that for another discussion.
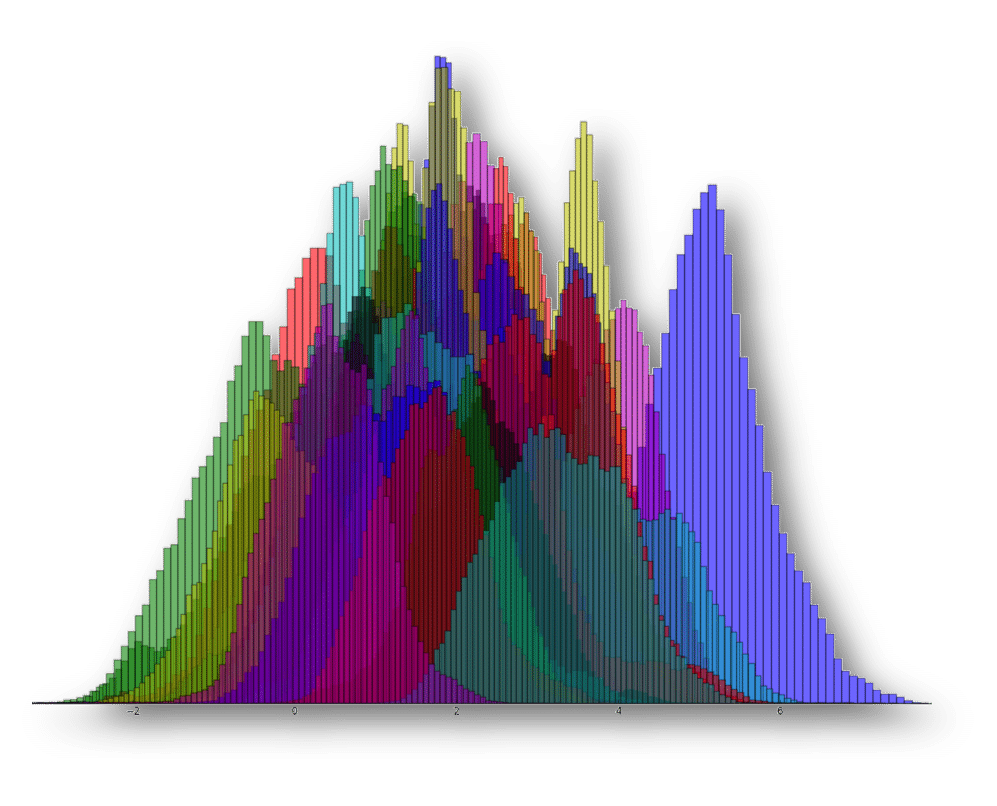
After testing out ridge regression and Bayesian linear regression (using pymc3), the requirements inferred from our observations of the above chart seem to hold. We need to find an algorithm that enables a non-linear representation of the data while capturing the uncertainty of the tournament. This leads us to pursue a Bayesian (to capture uncertainty) version of a neural network. The kind of neural network I decided to use is a simplified form called an Extreme Learning Machine (ELM). Again using pymc3, I am able to produce the following predicted distributions of depth into the tournament for 2013.
So what are we looking at? Each colored distribution represents a single team in the tournament, and their location on the x-axis represents how far the algorithm believes they will go in the tournament (1 is a loss in the 1st round and 7 is winning the whole thing). The blue distribution to the far right happens to be Louisville, the winner of the 2013 tournament! If we simulate 1 million tournaments using these distributions, the best bracket we generate gets 51 games correct of 63. If we had entered this bracket in ESPN’s bracket contest in 2013, we would have tied for first place among 8.15 million entrants!
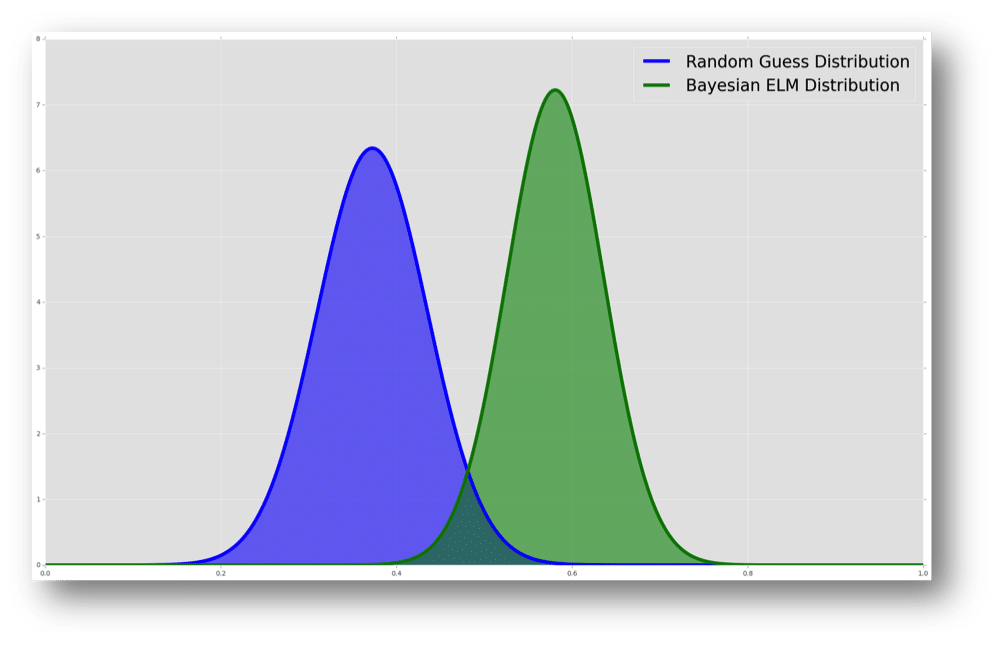
Going back to our process, we want to make sure that this 51 of 63 isn’t just due to luck. With a simple change to our analysis, I implemented the “dumb” learner, as I referred to it above. This learner is simply a random selection of a winner for each game in the tournament (a 50/50 chance for either team to win). Below, we take a look at how the “random” learner compares to our implementation of the Bayesian ELM.
This chart shows the fitted distribution of accuracy for each of the random and the Bayesian ELM over 10 million simulated brackets (0.0 on the x-axis is no games correct and 1.0 is predicting all games correct). This clearly demonstrates that the Bayesian ELM is indeed adding a significant amount of information to our predictions (good news!).
So you might be wondering, “Ok… how well did this do in 2015?” Using the same method for the 2015 tournament, and simulating 1 million brackets, the best one gets 52 games correct out of 63. When you use the scoring method ESPN uses and compare the our best prediction, we get 1750 points, which is plenty to crack the top 1% of all 11.5 million entries. We only needed to have 1450 points to be within that mark.
When simulating 10 million brackets with our method, we achieve 1800 points, which puts us in the top 0.001%. Even with this score, it’s not enough to beat the winner, a twelve-year-old kid from the Chicago area who scored 1830 points. But we’re just going to call that lucky and move on 🙂
As always, it’s a good idea to review our results and see what can be improved. Based on some more research, I would be interested in trying a new method called mixture density networks (which may be able to better represent the uncertainty of the tournament). Additionally, considering new factors such as the location of each game or team’s winning streaks may prove to be fruitful. In any case, a pretty fun set of results.
If you are interested in seeing a video of me presenting this material at the Atlanta Data Science Meetup, take a look here.
Until next time! Read parts one and two of this series. Comment below with questions on how to get started with data science problems.