Pindrop Reveals TTS Engine Behind Biden AI Robocall
Vijay Balasubramaniyan
Chief Executive Officer • January 25, 2024 (UPDATED ON October 30, 2025)
5 minutes read time
In a groundbreaking development within the 2024 US election cycle, a robocall imitating President Joe Biden was circulated. Several news outlets arrived at the right conclusion that this was an AI-generated audio deepfake that targeted multiple individuals across several US states.
However, many mentioned how hard it is to identify the TTS engine used (“It’s nearly impossible to pin down which AI program would have created the audio” – NBC News). This is the challenge we focussed on, and our deep fake analysis suggests that the specific TTS system used was ElevenLabs. Additionally, we showcase how deepfake detection systems work by identifying spectral and temporal deepfake artifacts in this audio. Read further to find out how Pindrop’s real-time deepfake detection detects liveness using a proprietary continuous scoring approach and provides explainability.
Pindrop’s deepfake engine analyzed the 39-second audio clip through a four-stage process: audio filtering & cleansing, feature extraction, breaking the audio into 155 segments of 250 milliseconds each, and continuous scoring all the 155 segments of the audio.
After automatically filtering out the nonspeech frames (e.g., silence, noise, music), we downsampled this audio to an 8 kHz sampling rate, mitigating the influence of wideband artifacts. This replication of end-user listening conditions is crucial for simulating typical phone channel conditions needed for unbiased and authentic analysis.
Our system extracts low-level spectro-temporal features, runs through our proprietary deep neural network, and finally outputs an embedding as a “fakeprint.” A fakeprint is a unit-vector low-rank mathematical representation preserving the artifacts that distinguish between machine-generated vs. generic human speech. These fakeprints help make our liveness system explainable. For example, if a deepfake was created using a text-to-speech engine, they allowed us to identify the engine.
Our deepfake detection engine continuously generates scores for each of the 155 segments using our proprietary models that are tested on large and diverse datasets, including data from 122 text-to-speech (TTS) engines and other techniques for generating synthetic speech.
Our analysis of this deepfake audio clip revealed interesting insights
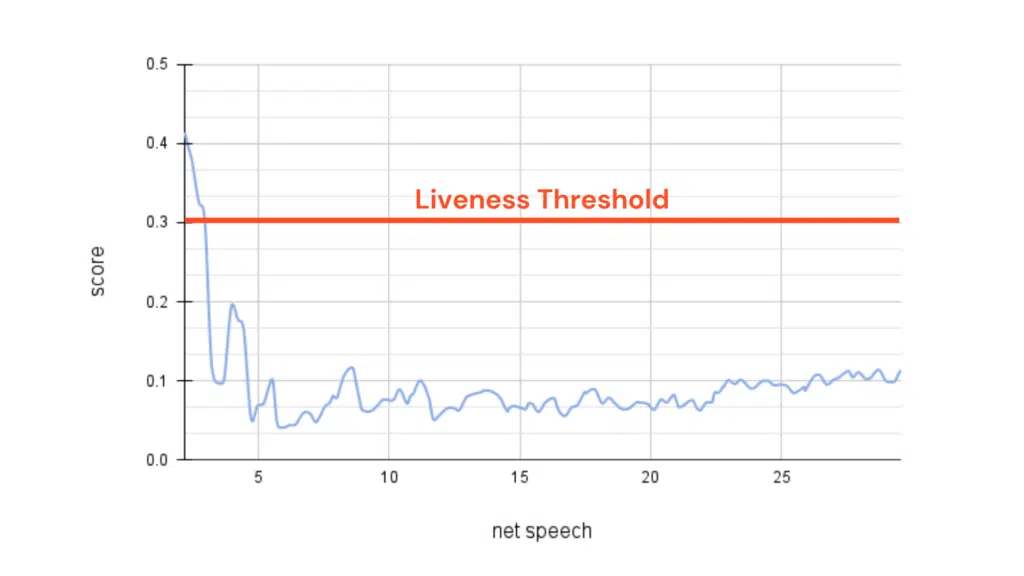
Liveness Score
Using our proprietary deepfake detection engine, we assigned ‘liveness’ scores to each segment, ranging from 0 (synthetic) to 1.0 (authentic). The liveness scores of this Biden robocall consistently indicated an artificial voice. The score fell below the liveness threshold of 0.3 after the first 2 seconds and stayed there for the rest of the call, clearly identifying it as a deepfake.
Liveness analysis of President Biden robocall audio
TTS system revealed
Explainability is extremely important in deepfake detection systems. Using our fakeprints, we analyzed President Biden’s audio against the 122 TTS systems typically used for deepfakes. Pindrop’s deepfake detection engine found, with a 99% likelihood, that this deepfake is created using ElevenLabs or a TTS system using similar components.
We ensured that this result doesn’t have an overfitting or a bias problem by following research best practices. Once we narrowed down the TTS system used here to ElevenLabs, we then validated it using the ElevenLabs SpeechAI Classifier, and we obtained the result that it is likely that this audio file was generated with ElevenLabs (84% likely probability).
Even though the attackers used ElevenLabs this time, it is likely to be a different Generative AI system in future attacks, and hence it is imperative that there are enough safeguards available in these tools to prevent nefarious use. It is great that some Generative AI systems like ElevenLabs are already down this path by offering “deepfake classifiers” as part of their offerings. However, we suggest that they also ensure the consent for creating a voice clone is actually coming from a real human.
Prior to determining the TTS system used, we first determined that this robocall was created using a text-to-speech engine, implying that this was not simply an instance of a person changing their voice to sound like President Biden using a speech-to-speech system. Our analysis also confirms that the voice clone of the President was generated using text as input.
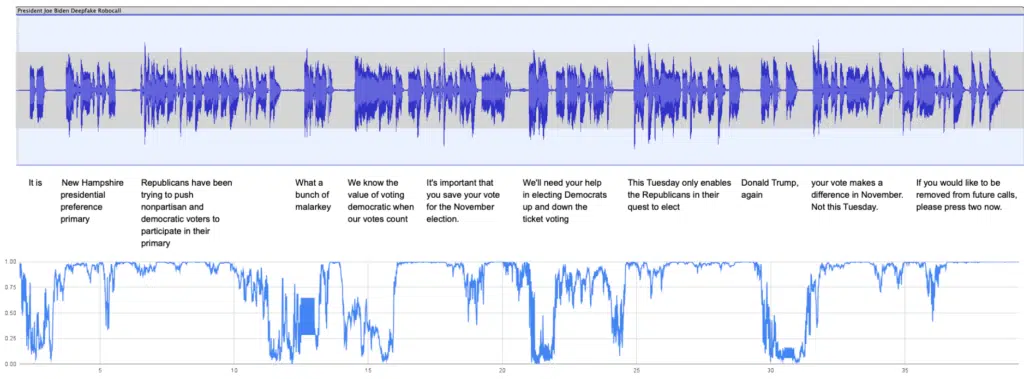
Deepfake artifacts
As we analyzed each segment of the audio clip, we plotted the intensity of the deepfake in each segment as the call progressed. This plot, depicted below, shows that some audio parts have more deepfake artifacts than others. This is the case for phrases like “New Hampshire presidential preference primary”, or “Your vote makes a difference in November.” This is because these phrases are rich with fricatives, like in the words “preference” or “difference,” which tend to be strong spectral identifiers for deepfakes. Additionally, we saw the intensity rise when there were phrases that President Biden is unlikely to have ever said before. For example, there were a lot of deepfake artifacts in the phrase: “If you would like to be removed from future calls, please press two now”. Conversely, phrases that President Biden has used before showed low intensity. For example, the phrase “What a bunch of malarkey”. This is something we understand President Biden uses a lot.
Protecting trust in public information + media
In summary, the 2024 Joe Biden deepfake robocall incident emphasizes the urgency of distinguishing real from AI-generated voices. Pindrop’s advanced methods identified this deepfake and its use of a text-to-speech engine, highlighting scalability.
Companies addressing deepfake misinformation should consider criteria like continuous content assessment, adaptability to acoustics, analytical explainability, linguistic coverage, and real-time performance when choosing detection solutions.
Acknowledgements:
This work was carried out by the exceptional Pindrop research team.
Partner with Pindrop to defend against AI-driven misinformation. Contact us here to talk to an expert.
Related research + insights
Access expert research, detailed guides, and practical resources on voice security to strengthen your contact center’s defenses.


Article
AI Attacks in Healthcare: Bots, Deepfakes, and Rising Risk
March 24, 20265 minutes read time

Article
Extending GitLab’s Findings: What Hiring Telemetry from Pulse for Meetings Reveals
February 25, 20268 minutes read time