From May 11-16, 2026, Pindrop researchers are attending the Language Resources and Evaluation Conference (LREC) 2026, an event that brings together professionals and scholars in natural language processing, computational linguistics, and speech and multimodality to discuss advancements and research in these fields.
Spotlights and blindspots: How we evaluated machine-generated text detection
This year, we submitted a paper titled, “Spotlights and Blindspots: Evaluating Machine-Generated Text Detection.”
As AI writing tools explode in popularity, so have the tools designed to detect it. But here’s the problem: It’s difficult to know how well detection models actually work, due to inconsistent testing and lack of clear measurement frameworks.
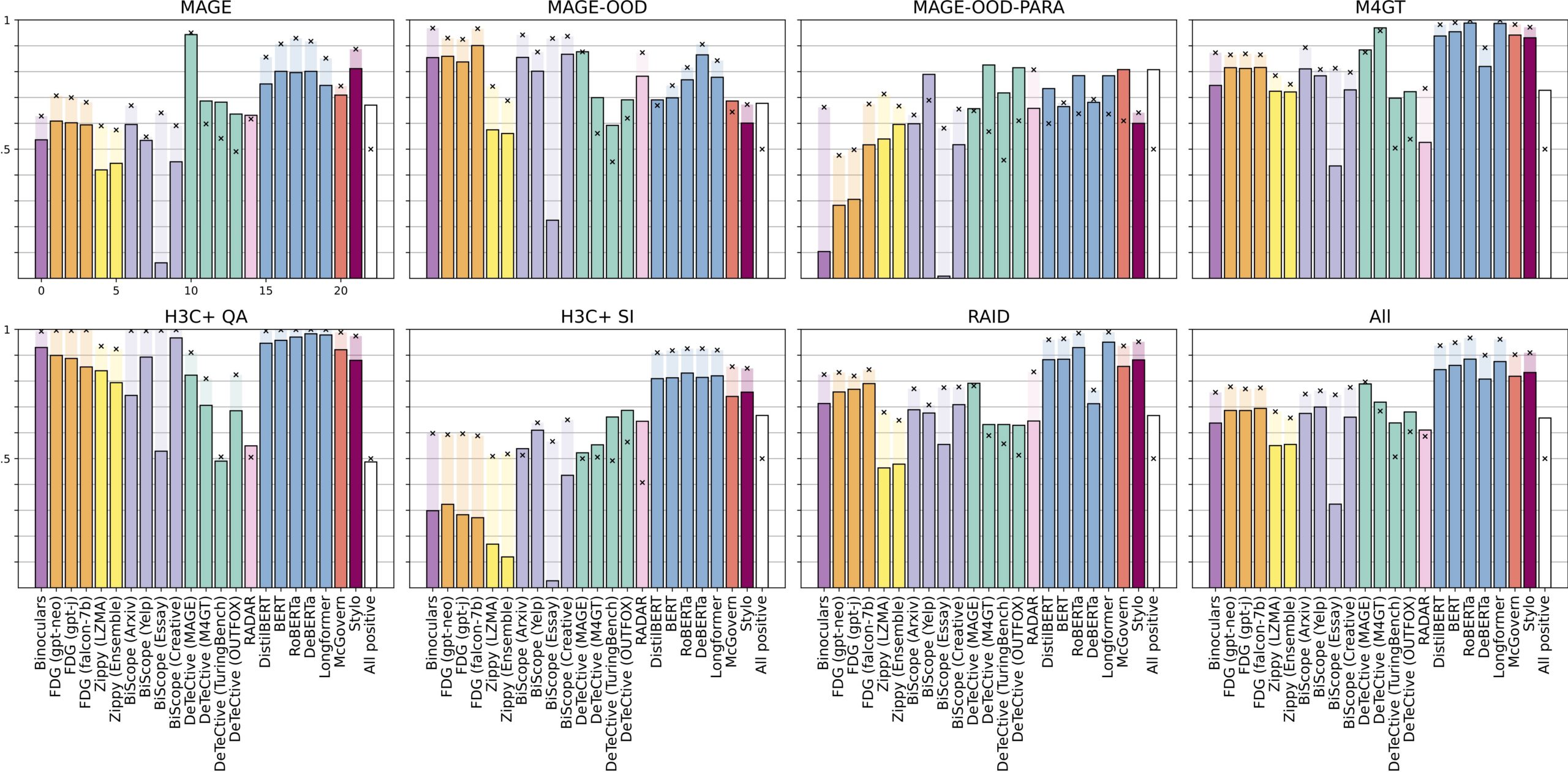
That’s why we ran a broad evaluation, testing 15 detection models from six systems and seven trained models across ten different datasets. We aimed to figure out how well these tools actually perform and what contributes to better performance. Keep reading to learn what we found.
No single model was the clear winner
When comparing across evaluation criteria, no model significantly outperformed the others across the board.
An F1 score is a machine learning measurement that looks at the precision and recall of the model and ranks it on a scale of 0 to 1. The F1 scores for the detection models we tested ranged from ~0 to 0.982, depending on the dataset. This revealed that the evaluation criteria you choose can significantly mask or inflate a model’s measured performance.