AI Has Broken Trust. Here’s How We’re Rebuilding It

Sarosh Shahbuddin
Senior Director, Product Management • July 24, 2025 (UPDATED ON September 15, 2025)
CONTRIBUTORS
Elie Khoury, VP of Research
9 minutes read time
On Tuesday at the Federal Reserve Meeting, Sam Altman sounded the alarm:
“A thing that terrifies me is apparently there are still some financial institutions that will accept a voice print as authentication for you to move a lot of money or do something else – you say a challenge phrase, and they just do it… AI has fully defeated most of the ways that people authenticate currently, other than passwords.”
He’s right—but not because voice biometrics is broken, but because single-factor trust always was.
The principle hasn’t changed in 20 years: no single authentication factor is ever enough.
What has changed—thanks to generative AI—is the order in which we have to ask our questions.
Before, it was enough to ask: Is this the right person? Now, we have to start with something even more fundamental:
Is this a real human at all?
That shift—from right human to real human—is reshaping the entire trust model for remote interactions. And it’s why detection has to come before authentication.
Single factor is never enough—you need defense in depth
Long before generative AI, the security industry understood that relying on a single factor was fragile. Combining factors, something you know, something you have, or something you are, has been embedded in security standards for decades.
A brief timeline of multi‑factor guidance
| Year | Standard / Guidance | Key Point on Multi‑Factor |
|---|---|---|
| 2004 | PCI DSS v1.0 (Payment Card Industry Data Security Standard) | Required multi‑factor authentication for remote access to cardholder data environments. |
| 2005 | ISO/IEC 27001 (Information Security Management) | Recommended defense‑in‑depth and layered access controls. |
| 2006 | NIST SP 800‑63 (first edition) | Introduced concepts of assurance levels and recommended multi‑factor to strengthen authentication. |
| 2018 | PSD2 (EU Strong Customer Authentication) | Mandated multi‑factor authentication for online payments. |
| 2019 | FIDO2 / WebAuthn | Public‑key MFA standard, eliminating shared secrets and strengthening layers. |
| 2021 | FFIEC – Authentication in an Electronic Banking Environment | Declared single-factor authentication inadequate for high-risk transactions. |
What’s changed today is the sequence of trust: we must first determine whether the user interacting with a system is a real human (and not a bot, synthetic voice, face, or signal) and only then apply “right human” technologies like multi‑factor authentication to confirm identity.
We saw the deepfake era coming—years before ‘deepfake’ existed.”
Back in 2014, before the term “deepfake” even existed, Pindrop’s research team was already studying these weaknesses. In a landmark INTERSPEECH paper, we evaluated a voice biometric system using the NIST Speaker Recognition Evaluation 2006 (SRE06) dataset, a benchmark collection of thousands of real phone calls, designed by the U.S. National Institute of Standards and Technology to test how well systems can match speakers across different sessions, devices, and environments.
The results were striking. Without a spoof detector, a world‑class voice analysis system that had only a 1.75% error rate under normal conditions suddenly became fragile under attack. Voice conversion attacks succeeded 6% to 15% of the time, a six‑to-eight‑fold jump in false accepts.
And this pattern isn’t unique to voice. There are decades of research papers showing similar weaknesses in other factors: passwords that can be phished or guessed, face recognition systems fooled by masks or photos, fingerprints lifted from surfaces, and more.
What makes deepfake detection hard—and how to build a robust defense system
Two forces have shifted the landscape: quality and prevalence. Synthetic voices now sound human‑level, and the number of available models has exploded, making high‑fidelity voice cloning accessible to anyone.
Improvement in Speech Quality
The leap in synthetic speech quality over the past two decades is staggering. One of the most common ways researchers quantify speech quality is through a Mean Opinion Score (MOS) – a listener‑based rating, typically on a 1 to 5 scale, where higher scores indicate more natural and intelligible speech.
MOS is widely used in telecom and speech research because it captures how humans perceive audio quality. It aggregates ratings from many listeners into a single, comparable metric.
Here’s a snapshot of the evolution of MOS for text‑to‑speech systems:

From 2 – 3.0 MOS in early systems to ≈4.8 MOS today, synthetic speech has now crossed human parity.
It’s important to note that MOS actually measures average perceived naturalness and intelligibility over short, de‑contextualized clips. A system can achieve high MOS while still failing to persuade a human listener or a voice biometrics system that it’s the target speaker.
Voice cloning models are exploding. So are the attack vectors.
One metric we follow here at Pindrop is how many open source models are available on platforms like Hugging Face, which has seen explosive growth in TTS models:
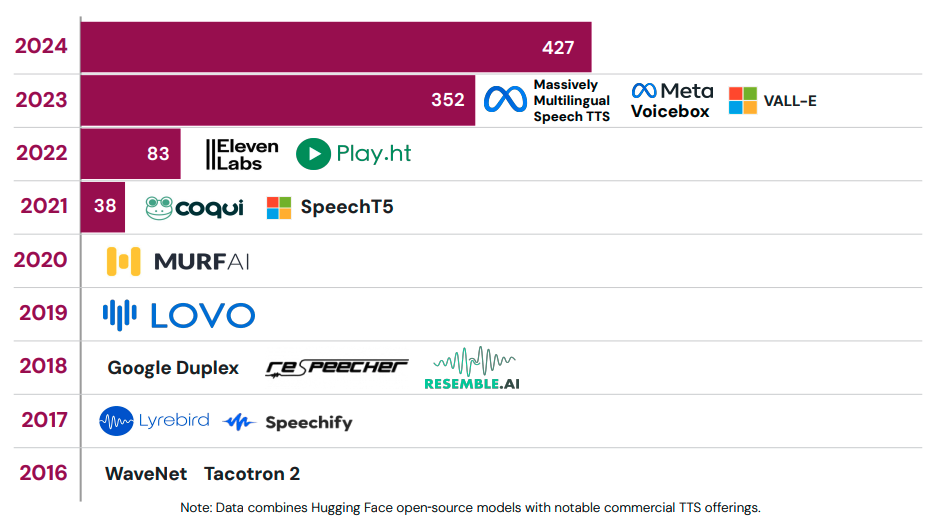
Total TTS model availability as of mid-2025 has now jumped to around 3,200 models. We also track unique models, not just project forks, clones, or language support, which still exceeded 900 unique models by early 2025.
While not every model is used maliciously, broader availability widens access to advanced voice synthesis tools, which is why we track these trends closely.
From thousands of models, one lesson: every synthetic voice has a signature
When people say “AI generator” or “text‑to‑speech generator,” it sounds like a single black‑box system. In reality, these engines are layer cakes of machine learning models working together: a phoneme converter that turns text into sound units, audio encoders and decoders, neural codec language models, vocoders that shape the waveform, and more.
Each combination can produce slightly different artifacts, quirks, and telltale fingerprints as we highlighted in a previous study.
At Pindrop, we’ve spent years watching this ecosystem explode. Every new release from an open‑source community or a private lab adds another dimension to the challenge. To keep up, our solution’s underlying models train on a steady stream of outputs from both open‑source and proprietary engines, learning not just the obvious differences but the subtle acoustic patterns that signal synthetic speech.
Over time, you can see the growth in the numbers:
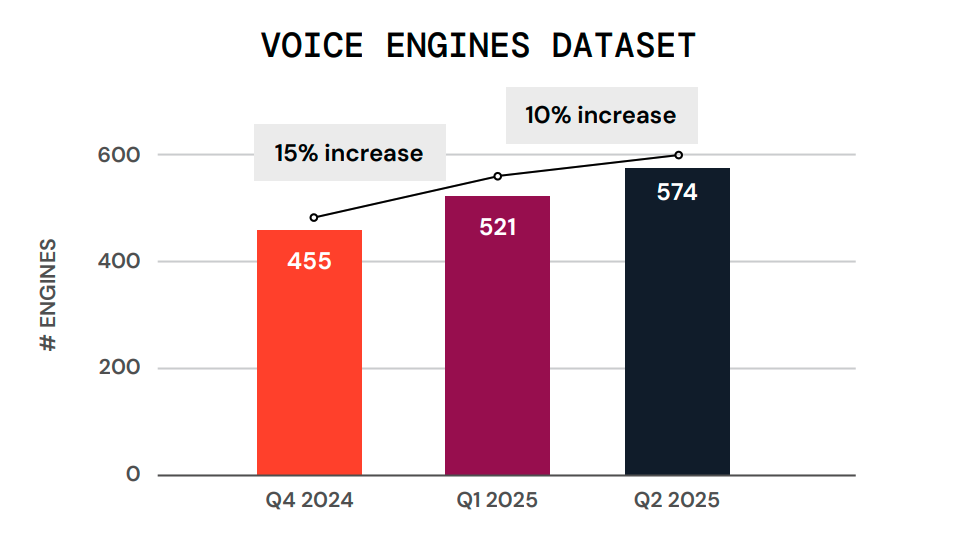
And every one of those engines doesn’t just produce a single clip – we generate thousands of utterances. We feed our detectors this constantly expanding library so they can sharpen their instincts against even the most elusive anomalies.
Pindrop researchers don’t just generate a single clip from these models—we produce thousands of audio utterances from each engine. Those utterances are then used to train and refine the underlying machine‑learning models that power the Pindrop detection products, sharpening their ability to spot even the most elusive anomalies. Today, we have over 30 million utterances in our development data.
Constant updates to model growth mean one thing: the solution gets smarter every time a new engine appears. Our Deepfake detection solutions, PindropⓇ Pulse, learns the nuances, quirks, and anomalies so that as the layers of those models are stacked, the solution can still tell the real from the fake.
We Test for Zero‑Day Attacks
Because Pulse is trained on a diverse set of voice engines—over 500 architectures reflecting how today’s generators are built—it doesn’t just memorize known patterns. It learns the underlying signals that let it generalize to what it’s never heard before.
To prove it, we don’t just test Pulse on familiar data. Our Red Team constantly throws it into the deep end, attacking with voice engines and generation methods that have never been part of its training set.
The results speak for themselves: in Q4 of 2024, Pulse hit 90% accuracy on zero‑day attacks—models it had never seen. Today, we’ve pushed that to 93.2% detection on completely unseen models.
Every quarter, accuracy against these zero‑day attacks continues to climb, showing that diversity in training truly pays off when the unknown shows up.
Training on tomorrow’s engines—before they’re public
We don’t just rely on the audio or video that shows up in the wild. We actively collaborate with the teams building generative AI technology so we can use their outputs to train our models before those engines are released.
By working directly with organizations like NVIDIA, Respeecher, and others, soon to be announced, we get early access to models, datasets, and outputs. That advanced exposure lets us train and harden our systems ahead of time.
The result: our detectors are ready for emerging voice engines long before attackers can exploit them. By partnering early, we stay ahead—training on tomorrow’s engines before they ever hit the wild.
The new sequence of trust: real human first. right human second.
If there’s one takeaway from all of this, it’s that single-factor authentication is broken. Passwords, biometrics, or tokens alone have all been defeated in research and practice.
That’s why the industry moved to multi‑factor authentication, the foundation of every Right Human platform: layering voice, device, behavior, and other signals to confirm the right human.
But as Sam Altman rightly pointed out, the game has changed. Before we even get to the right human, we have to answer a more fundamental question:
Is this a real human?
While this piece has focused on audio, the same principles apply to video. Whether it’s a contact center call or a high-stakes video conference, the future of trust isn’t just multi-factor authentication—it’s Real Human + Right Human working in tandem.
That’s the technologies we’re building: a system that can tell if the person on the other side is really a human, and then verify that they are authorized.
Because trust in digital interactions doesn’t stop at one factor, and it never will.
Related research + insights
Access expert research, detailed guides, and practical resources on voice security to strengthen your contact center’s defenses.

Article
Zero Trust Came for the Network. Now It’s Coming for the Human.
July 16, 202612 minutes read time

Article
Deepfake Video Call Scams & BEC: The Case for Continuous Identity Verification
July 7, 202611 minutes read time
