Pindrop’s ICASSP Papers Aim to Upgrade Audio Analysis
Pindrop
May 10, 2022 (UPDATED ON October 30, 2025)
4 minutes read time
From proposing new paradigms to cost-saving accuracy improvements, our research team is all over the ICASSP, an industry-leading human-centric signal processing conference. Let’s take a look at Pindrop’s three paper submissions to learn more about these innovations.
Note: The experimental results presented in these papers do not reflect the performance of our products.
Paper 1: Distribution learning for age estimation from voice
The research team here at Pindrop decided to take a new approach to improve age range estimation just from a speaker’s voice. Instead of looking at it as a classification or regression problem, we look at it as a distribution learning problem. After looking into how distribution learning is used for facial recognition, the first apparent obstacle identified is that audio research lacks datasets with “apparent” age. The research conducted, however, shows that the promises of distribution learning validated for facial age estimation still hold for audio, that is, when humans estimate someone’s age range (from image or voice), it is relatively easy for them to give an age range estimate with a particular confidence interval. We were able to beat out the traditional approaches under most conditions.
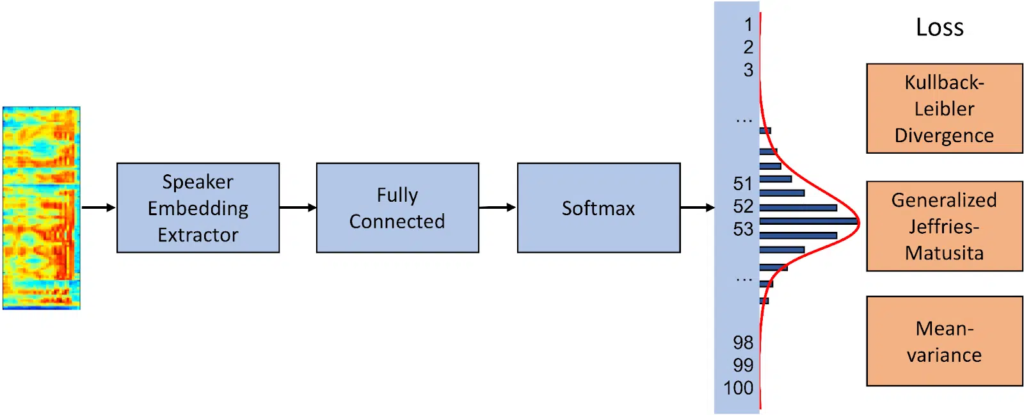
Fig 1: Proposed age estimation: The front-end extracts speaker embeddings from voice utterances. The back-end is trained using Gaussian-based distribution learning losses.
Paper 2: Speaker Embedding Conversion for Backward and Cross-Channel Compatibility
Automatic speaker verification (ASV) systems have been growing in accuracy thanks to breakthroughs in low-rank speaker representations and deep learning techniques. At Pindrop, we refer to ASV as ‘voice authentication,’ and this technology has led to the success of voice authentication in real-world applications from contact centers to mobile applications and smart devices.
When looking at compatibility between voice models, our research team found that many providers of voice authentication technology have been migrating their models to newer deep learning paradigms, making embeddings from legacy versions incompatible with newer versions. They have proposed a novel DNN-based method to facilitate this model upgrade to allow for backwards compatibility.
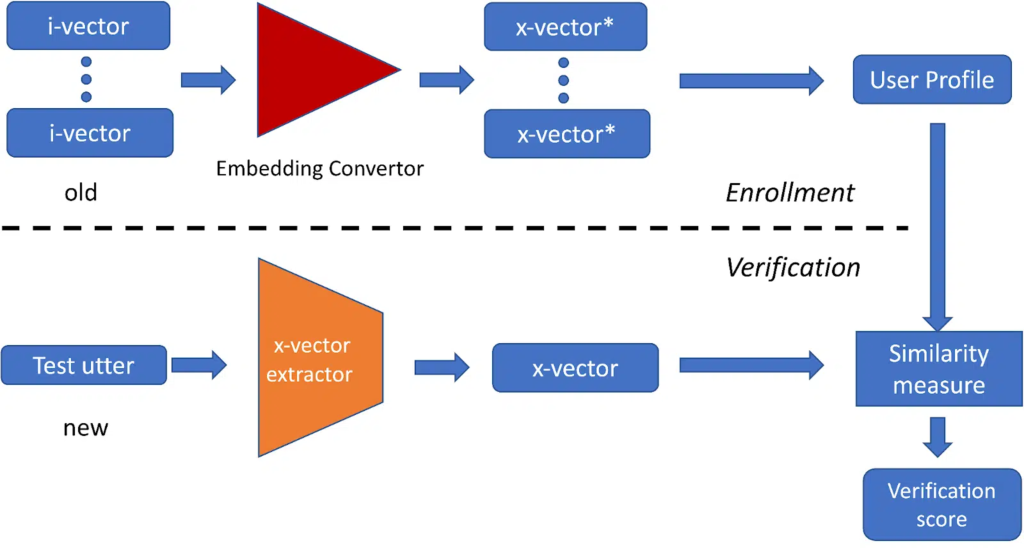
Fig 2: Overview of the proposed ASV system. The system uses the embedding convertor to transform the old enrolled i-vectors into the “converted” x-vectors* that could be directly compared with the newly acquired test x-vector.
The research team also found that their new DNN-based model works without impacting customers, while reducing engineering and computational cost overhead.
Paper 3: Unsupervised Model Adaptation for End-to-End ASR
State-of-the-art Automatic Speech Recognition (ASR) systems are widely used in our devices and communications systems. When you call your bank, a robot voice asks you to “say or press 1,” for example. The system transcribes your audio so the computer can point you in the right direction. However, these ASR systems can be flawed, underperforming in mismatched train-test conditions like call centers where it’s difficult to account for accent, voice audio quality, etc.
To solve for this, the research team has proposed a cost-effective way to improve accuracy of ASR systems using in-domain data without the need for costly human annotations. This was made possible by exploring the relationship between the word-error-rate (WER) and the CTC loss on one hand, and the WER and the probability ratio based confidence (PRC) on the other hand., as illustrated in Figure 3. Results show that we could reduce the WER by 8% (absolute) in a completely unsupervised way, basically allowing the ASR model to adapt itself to accommodate for suboptimal conditions.
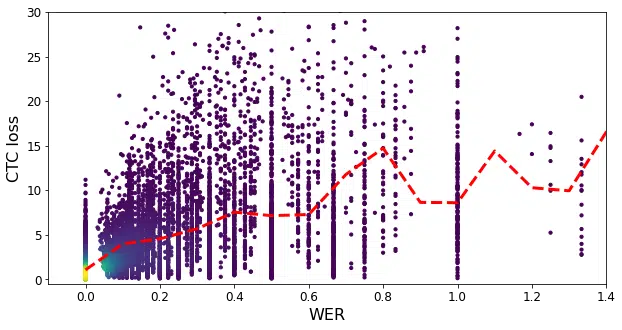
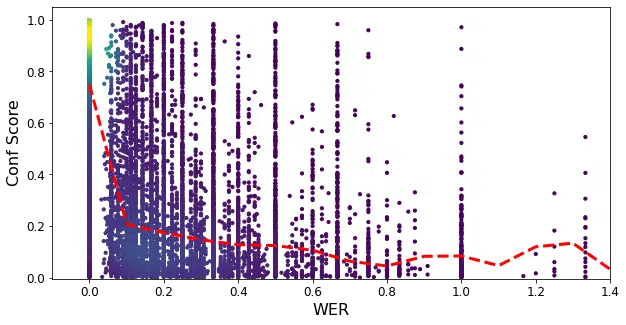
Fig 3: Scatter plots of CTC loss vs WER, PRC vs WER for the utterances from the HarperValleyBank dataset.
Note: The experimental results presented in these papers do not reflect the performance of our products.
Related research + insights
Access expert research, detailed guides, and practical resources on voice security to strengthen your contact center’s defenses.

Article
AI Attacks in Healthcare: Bots, Deepfakes, and Rising Risk
March 24, 20265 minutes read time

Article
Extending GitLab’s Findings: What Hiring Telemetry from Pulse for Meetings Reveals
February 25, 20268 minutes read time

Case study
One Year Later: Michigan State University Federal Credit Union Minimizes Fraud Exposure by Millions
December 1, 20257 minutes read time