Earlier this year, we published data showing a 1,200% increase in AI-enabled fraud. That number understandably drew attention. But the magnitude of the spike is less interesting than its timing.
FS-ISAC 2026: Inside the 2025 Deepfake Inflection

Sarosh Shahbuddin
Senior Director, Product Management • March 13, 2026 (UPDATED ON March 13, 2026)
5 minutes read time
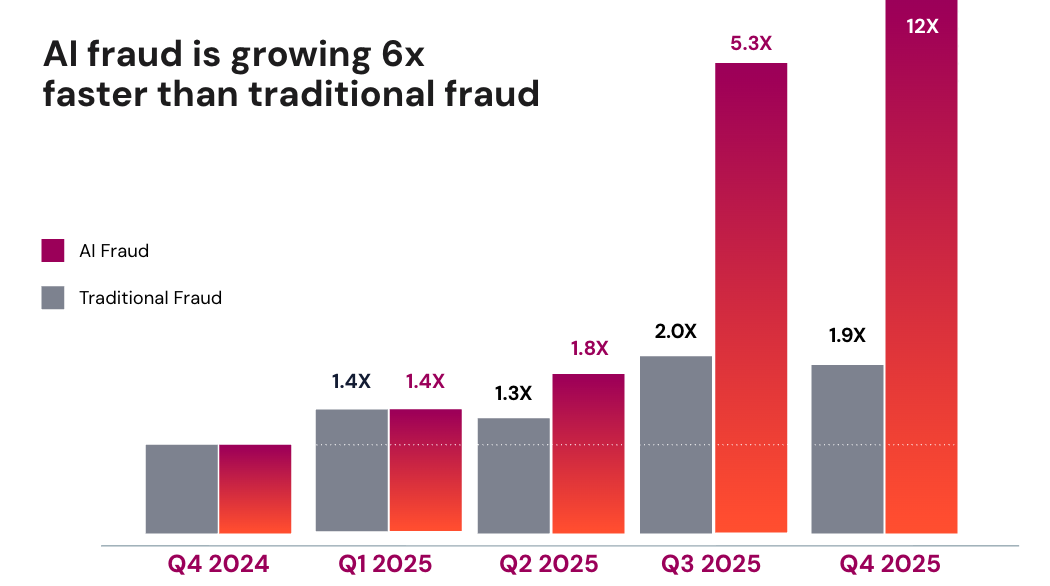
I had the opportunity to walk through these trends at the FS-ISAC 2026 Americas Spring Summit on March 1st. The conversation quickly moved past the headline number to a more important question: why did this happen in 2025?

Synthetic voices didn’t suddenly become realistic in 2025. High-quality text-to-speech systems had already reached impressive levels of naturalness. If realism alone were the gating factor, we would have seen this spike earlier.
The reason is that impersonation doesn’t succeed in the first few words. It’s won, or lost, over several minutes of conversation.
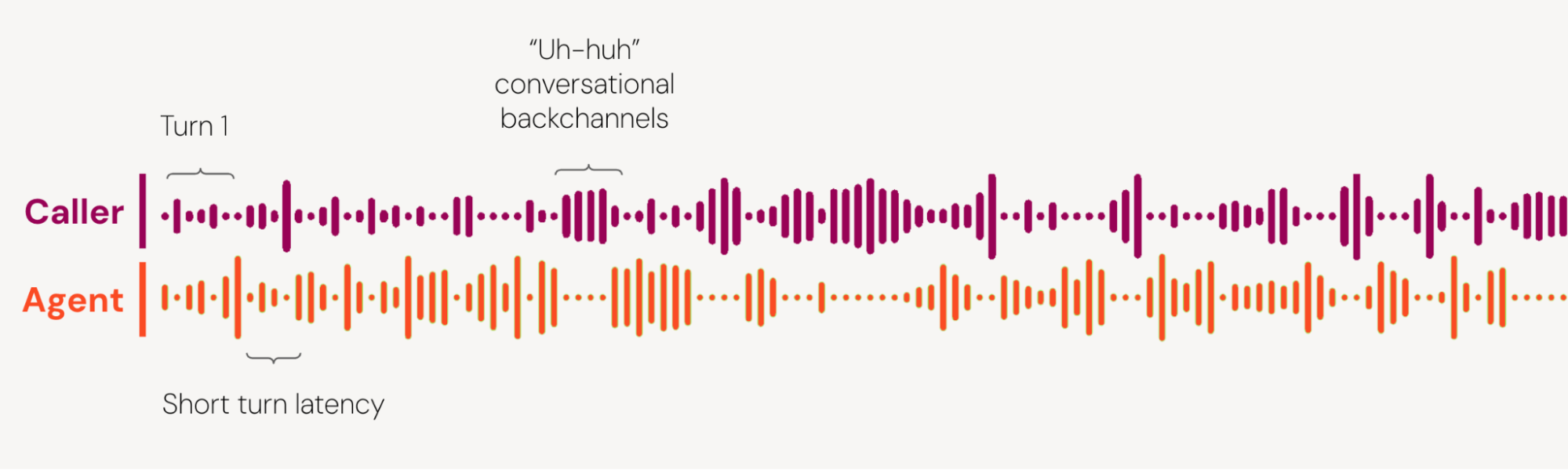
A typical financial services interaction in a contact center doesn’t include just a single utterance. It is a sustained, stateful exchange. A customer call flow can involve 60 to 150 conversational turns across several minutes. In more complex cases, it exceeds that. The interaction includes clarifications, corrections, overlapping speech, and conversational backchannels—the small signals like “uh-huh,” “right,” or “okay” that regulate turn-taking and signal engagement—along with dynamic questioning. The participant has to remain consistent, not just in voice quality, but in memory, timing, and behavior.
For years, that is where AI systems failed.
To understand this better, let’s look at a conversation from a machine learning model’s perspective. Conversations can be represented as a sequence of text, or tokens, with a fixed memory budget. Every spoken turn consumes part of that budget.
At roughly 250-300 tokens per turn, sustaining 60 turns requires on the order of 15,000 – 20,000 tokens of working context. At 150 turns, we approach 45,000 tokens.
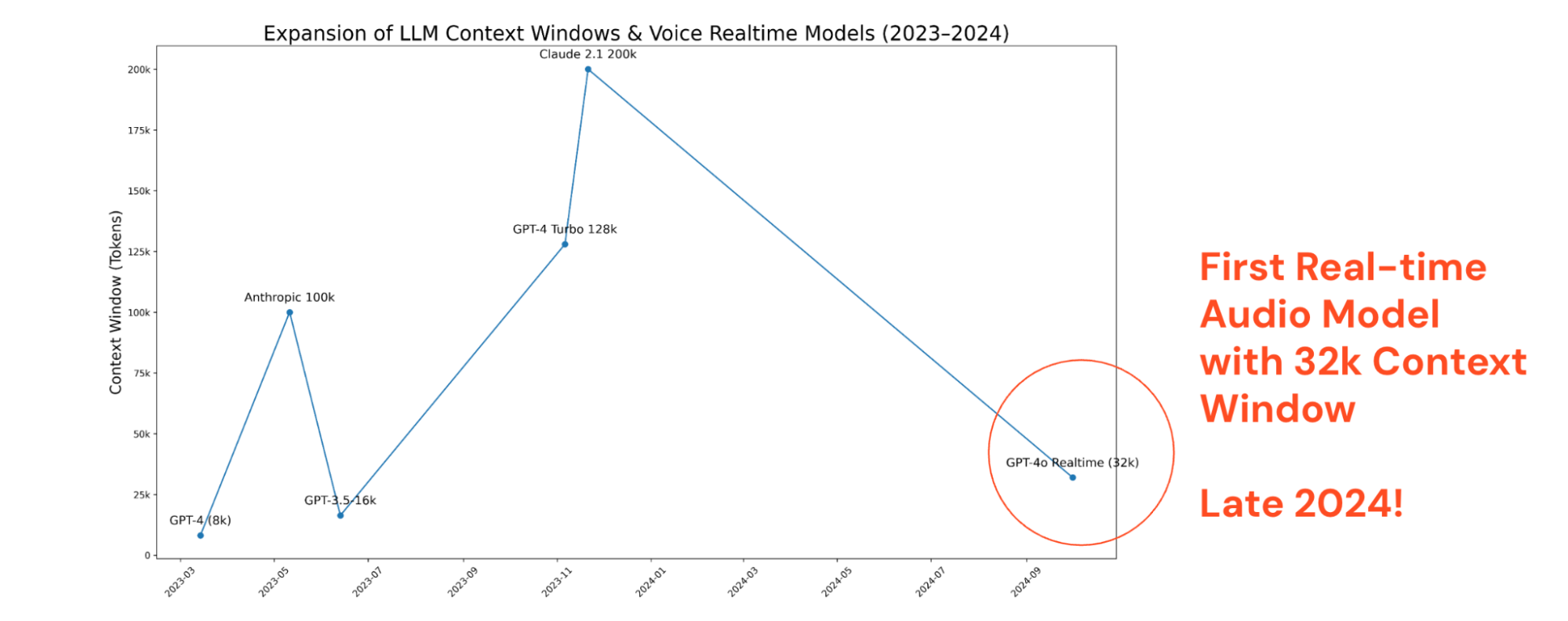
Note: Not shown here is Gemini 1.5 1m token context in Feb. 2024
Until late 2024, real-time audio systems rarely supported stable 32k-class context windows in streaming environments. Large-context models existed, but not with low-latency speech interaction. When context is insufficient, persona stability degrades. The system forgets earlier answers, subtly shifts tone, or loses grounding. Those failures are survivable in a demo. They are not survivable in an automated fraud attempt.
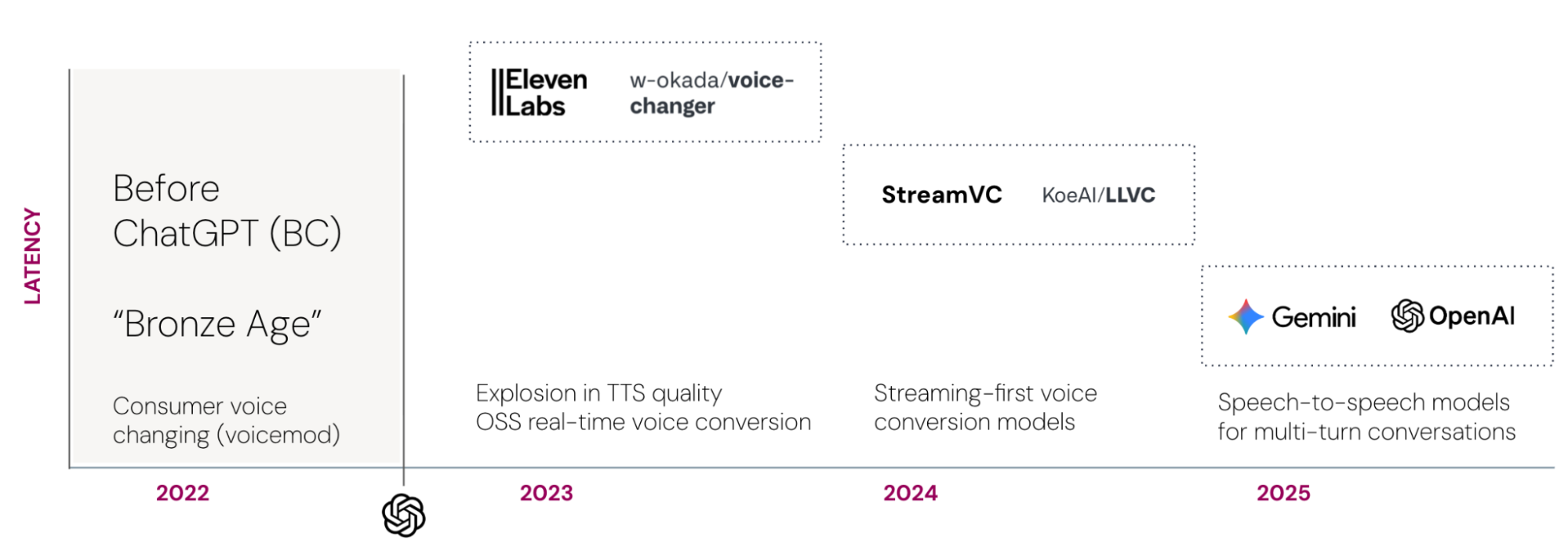
Memory was the first constraint to fall (late 2024 / early 2025).
Latency was the second.
In live conversation, response timing governs turn-taking. Time-to-first-audio (TTFA) is the speech analogue to time-to-first-token in text models – the delay between the end of a user’s utterance and the moment the system begins responding. In text, you see this as the moment the first word appears on screen. In voice, it is the moment audio begins.
GIF from Utkarsh Parashar, “How to stream output in LLM-based applications to boost user experience,” GoPenAI blog (October 11, 2023).
There appears to be a threshold around 1.2 seconds: below it, pauses register as cognition; above it, they register as latency. In 2025, multiple real-time speech-to-speech systems crossed below that threshold in benchmark measurements.
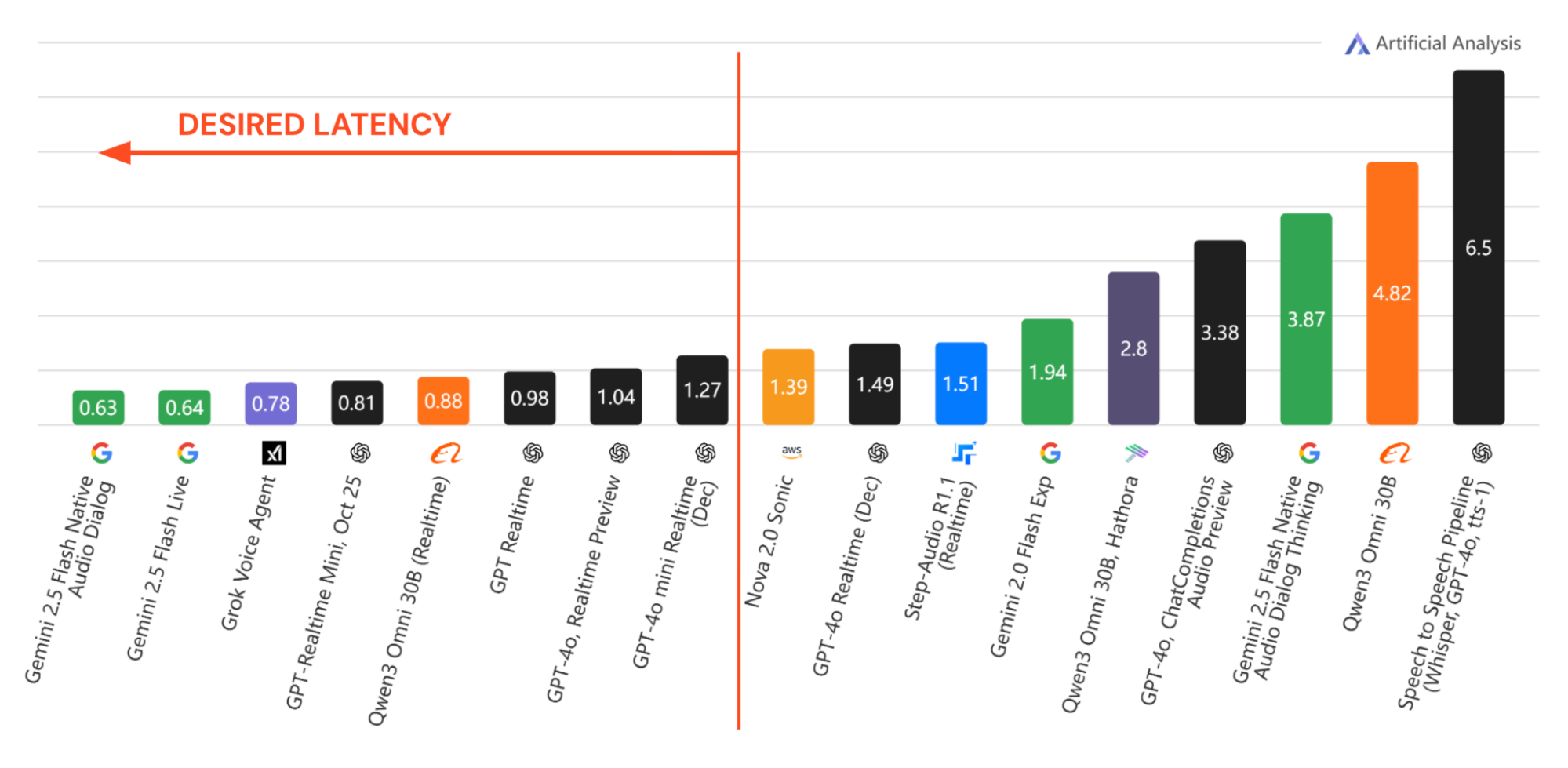
Image adapted from Artificial Analysis.
More importantly, the release pattern compressed. There are now at least eight speech-to-speech reasoning models operating at or below roughly 1.2 seconds time-to-first-audio. All eight were released in 2025. Four arrived in December alone. Two are open source, released under Apache 2.0 and MIT licenses.
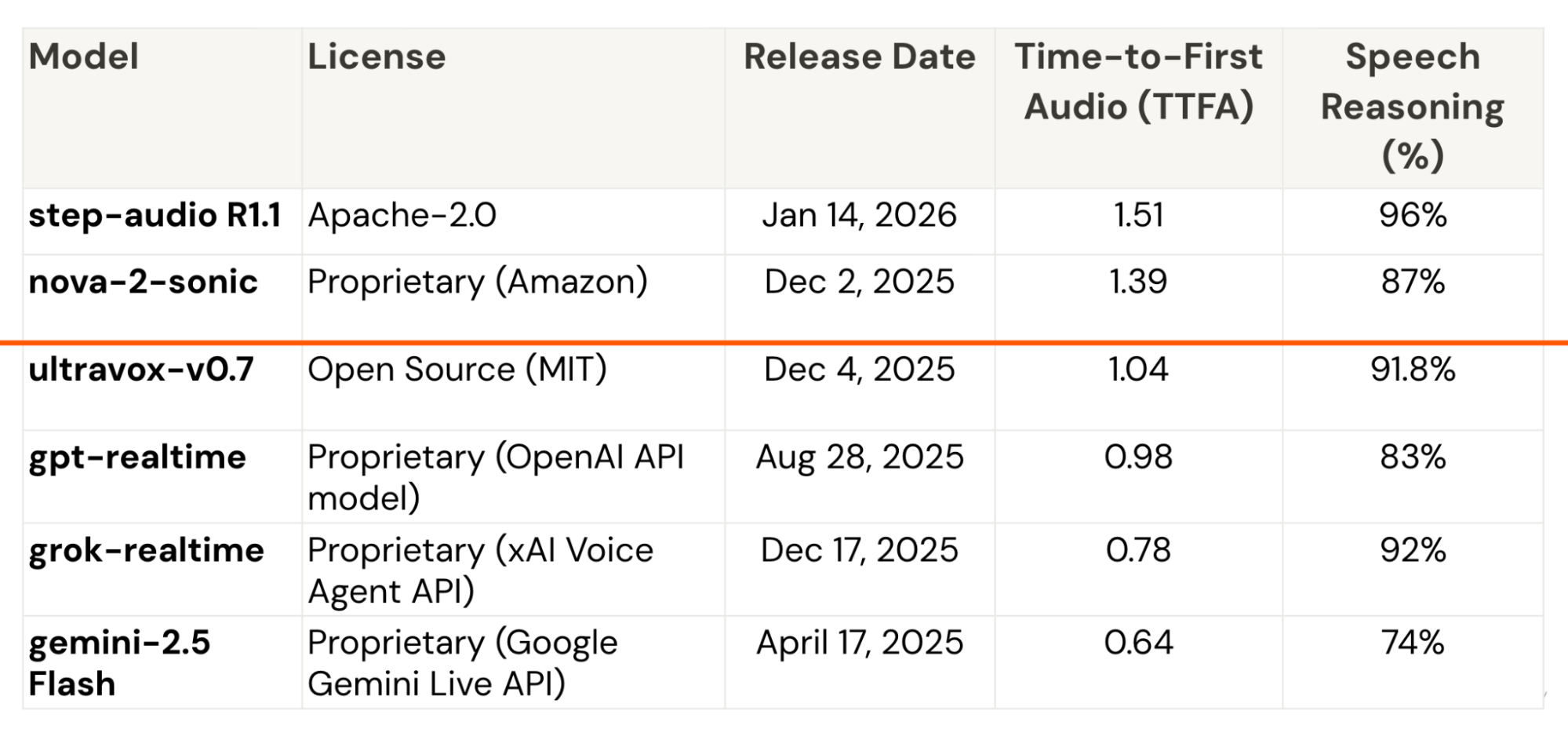
That concentration matters. When multiple vendors converge on the same latency band with high reasoning, within a single year, and when part of that capability diffuses into open source, the constraint is no longer marginal. It is gone.
At the same time, architecture shifted. Earlier systems effectively rebuilt the speaker each turn: transcribe speech, process tokens, synthesize a new waveform. Speech-native systems preserve acoustic representations across turns, improving cadence stability and interruption handling. The interaction stops feeling like a sequence of regenerated clips and starts feeling continuous.
While system capability improved, human detection moved in the opposite direction. In controlled classification tests we shared in 2025, human accuracy in identifying synthetic media varied by modality. One year later, the pattern compressed. Image and video detection converged toward roughly 50% – statistical randomness. Audio dropped further.


Human performance did not suddenly collapse. It shifted as the systems themselves became more capable. Longer context windows allowed models to maintain conversations across extended interactions. Faster responses stabilized turn-taking. Cross-turn consistency improved. As those failure points diminished, the cues that once separated authentic from synthetic became less reliable. Human prediction of audio, continuing to trend below chance-level detection, is therefore not surprising.
Seen in that context, the 1,200% increase is less an anomaly than an inflection. The technical barriers that once limited sustained, real-time impersonation were removed in 2025.
There is little reason to expect those barriers to return. If anything, the concentration of model releases at the end of 2025 suggests that the baseline capability entering 2026 is higher than it was a year ago. For fraud teams, that likely means AI-enabled attacks will continue to grow as a share of overall fraud, not recede.
2026 will not be a quiet year for fraud fighters.
Related research + insights
Access expert research, detailed guides, and practical resources on voice security to strengthen your contact center’s defenses.


Article
AI Fraud Accountability Act: The End of “Trust Your Ears.”
March 5, 20265 minutes read time

Case study
90% Drop in Fraud and a Smoother CX: How HealthEquity Did It
February 23, 20268 minutes read time